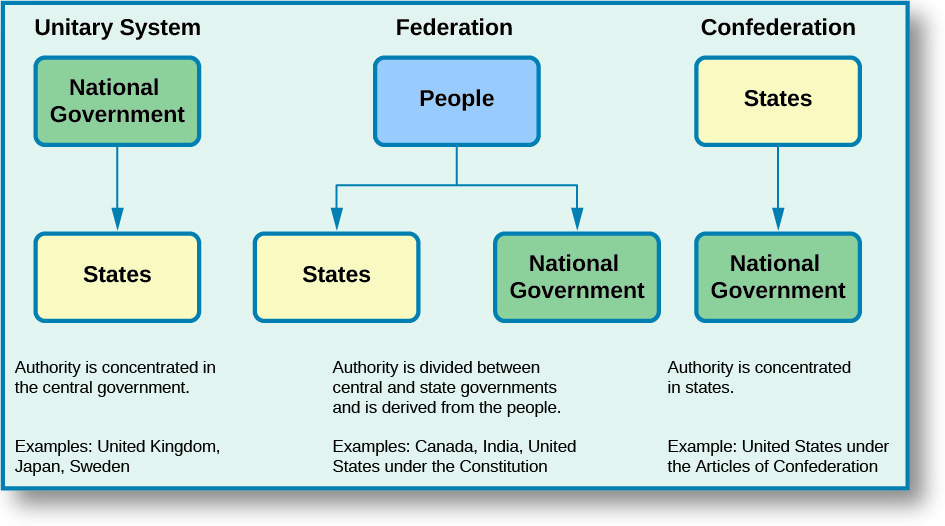
There are three different systems of government, which differ in how power is distributed between national/central government and governments of subnational/constituent units:
FEDERATION — significant government powers are divided between the central government and smaller governmental units
CONFEDERATION — constituent units or states retain ultimate authority and can veto major actions of the central government
UNITARY SYSTEM — the central government exercises all governmental powers and can change its constituent units
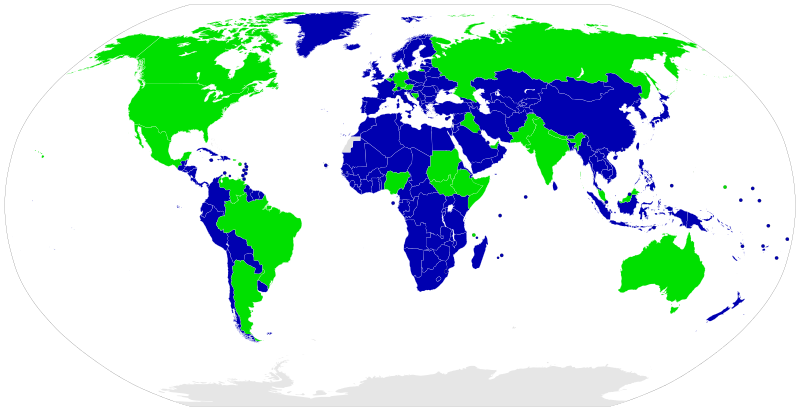
Unitary systems (countries shaded blue on the map below) are the most common way of organizing governments abroad. Most federal systems (countries shaded in green on the map below) are found in countries that are large and diverse.
Systems of Government Around the World. From Wikipedia
“[Texas] is America on steroids. Think of the characteristics that make America distinctive–its size and diversity, its optimism and self-confidence, its crass materialism and bravado, its incredible ability to make something out of nothing–and they exist in their purest form in Texas.”
– The Future is – Texas; Texas, 2002
Individualism
INDIVIDUALISM is the belief that individuals are responsible for their own welfare. Individuals are encouraged to have initiative and work hard to become successful in society. Through the lens of individualism, what is good for society is based on what is good for individuals, and “[g]overnment activity is encouraged only to the extent that it creates opportunity for individual achievement” (Roots of Texas Politics). Individualism helps to explain the “pull yourself up by your bootstraps” mentality of many Texans. Texas’s individualism is rooted in the state’s frontier heritage.
Traditionalism
TRADITIONALISM refers to upholding or maintaining tradition, particularly in resistance to change. Under traditionalism, the government is viewed as a mechanism through which the existing social order can be preserved; in other words, government action should reinforce the power of society’s dominant groups. Traditionalism, “emphasizing deference to elite rule within a hierarchical society and traditional moral values, represents the values of 19th century Southerners who migrated to the rich cotton land of East Texas” (Roots of Texas Politics).
Limited Government
Closely associated with individualism is the belief that the government must be limited in its power and responsibilities. The belief in limited government is a key component of U.S. political culture, which developed out of concerns that a powerful government is likely to threaten individual rights. Anglo-American settlers brought this belief in limited government with them as they began to colonize Texas. However, this belief did not arrive to Texas with empresarios and Anglo-Americam settlers; there were also many Mexican citizens who also favored limited government (known as the FEDERALISTAS). Texas’s experience as an occupied military district under Governor Davis during Radical Reconstruction solidified limited government as a cornerstone of Texas political culture, and the structure and functions of Texas’s government as outlined in the Texas Constitution of 1876 (Texas’s current constitution) epitomizes limited government.
Private Property, Free Enterprise, and Entrepreneurialism
PRIVATE PROPERTY (the ownership of property by private parties), FREE ENTERPRISE (an economic system in which private business competes in free market), and ENTREPRENEURIALISM (the ability to start new businesses) are all fundamental elements of capitalism. Texas is known for its ardent support of limited government regulations and free markets. As with the belief in limited government, these beliefs are rooted in Texas’s experiences as a territory of Spain and Mexico, in addition to the influence of Anglo-American settlers.
Rice and Sundberg examined the political culture of states through the framework of civic culture. CIVIC CULTURE is a political culture that is conducive to the development of an efficient, effective government that meets the needs of its citizens in a timely and professional manner.
Civic culture consists of the following elements:
Civic engagement – citizens participate in the policymaking process in order to promote the public good
Political equality – citizens view each other as political equals, with the same rights and obligations
Solidarity, trust, and tolerance – citizens feel a strong sense of fellowship with one another, tolerating a wide range of ideas and lifestyles
Social structure of cooperation – citizens are joiners, belonging to a rich array of groups
States with high civic culture have innovative and effective government. States with low civic culture are less responsive to citizen demands.
Texas is considered to have a very low civic culture, ranked 43rd out of 50.
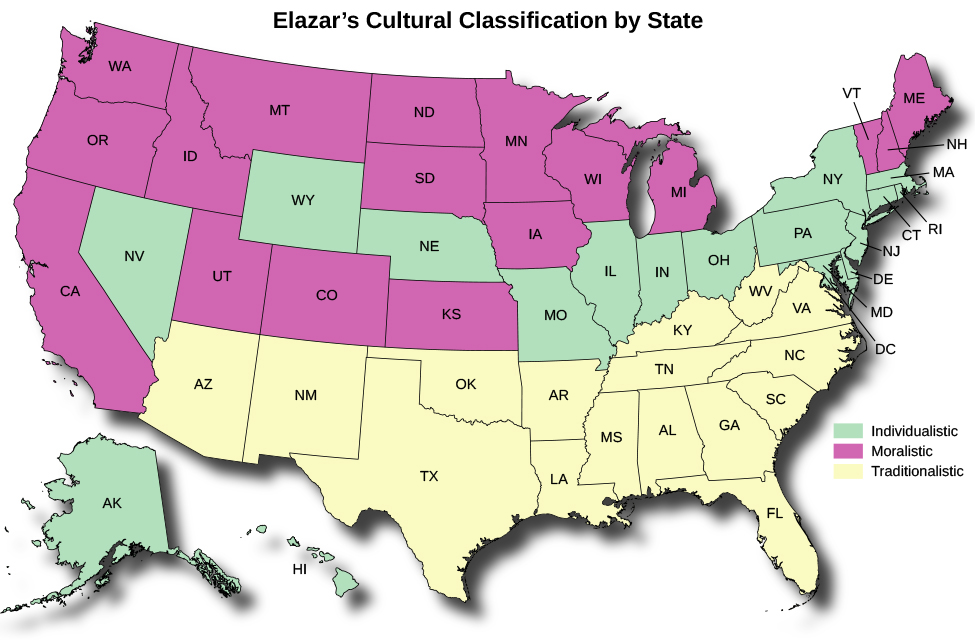
Daniel Elazar argued that the political culture within states of the United States could be geographically divided into three general types:
INDIVIDUALISTIC POLITICAL CULTURE, which emphasizes private initiative with a minimum of government interference. The role of government should be limited to protecting individual rights and ensuring that social and political relationships are based on merit rather than tradition, family ties, or personal connections
TRADITIONALISTIC POLITICAL CULTURE, which sees the role of government as the preservation of tradition and the existing social order. Government leadership is in the hands of an established social elite, and levels of participation by ordinary citizens in the policy-making process are relatively low
MORALISTIC POLITICAL CULTURE, in which people expect the government to intervene in the social and economic affairs of the state, promoting the public welfare and advancing the public good. Participation in political affairs is regarded as one’s civic duty
Elazar attributed this geographic distribution of individualistic, traditionalistic, and moralistic political cultures across states to migratory patterns of populations.
Texas = Hybrid
Texas has a hybrid political culture that includes both traditionalistic and individualistic elements.
Traditionalistic Characteristics
Long history as a one-party state
Low levels of voter turnout
Social and economic conservativism
Individualistic Characteristics
Strong support for private business
Opposition to big government
Faith in individual initiative
“Taken together, individualism and traditionalism make Texas a politically conservative state, hostile to government activity, especially government interference in the economy . . . However, while individualism and traditionalism generally reinforce a conservative political environment, they can also exist in uncomfortable tension with one another. For whereas the individualistic thread in Texas culture stresses individual freedom from government intrusion, the traditionalistic thread can foster the government’s promotion of particular moral values upon those very same individuals” (Roots of Texas Politics, n.d.).
Underlying every political system is a unique POLITICAL CULTURE, or commonly shared ideas, beliefs, and values about a nation or state’s history, citizenship, and government held by a population. Political culture is based on normative or prescriptive statements about how things ought to be and includes both formal rules and informal customs and traditions.
Political culture generally remains relatively stable over time because important ideas, beliefs, values, customs, and traditions are passed down generationally through the process of POLITICAL SOCIALIZATION. Various agents play a role in political socialization, notably family, school, and the media. Legends and folklore also serve as vehicles through which political socialization occurs.
Political culture often consists of diverse subcultures based on characteristics such as race, ethnicity, socioeconomic status, and geographic location. Furthermore, key political events and transforming experiences, such as wars and economic crises, can reshape attitudes and beliefs and cause shifts in political culture.
Because political culture is so deeply rooted and widespread, people are often unaware of how political culture influences their perception of reality. For this reason, it can be difficult to identify and analyze the components of political culture.
What Does Political Culture Do?
Provides political system with distinctive characteristics
Political culture significantly influences government and politics within a nation or state. Political culture shapes the way constitutions are written, the type of government institutions adopted, the boundaries of governmental authority, and the role of citizens.
Political culture binds us together
Political culture unites populations by focusing on what we have in common. Political culture also provides a framework for disagreement and conflict resolution by setting the boundaries of acceptable political behavior in society. Furthermore, political culture benefits political systems through cultivating and maintaining diffuse support characterized by political stability, acceptance of the legitimacy of government, and a common goal of preserving the system in place.
Texas is a large, diverse state. Below, we will examine some of the characteristics of the Lone Star State today.
Size
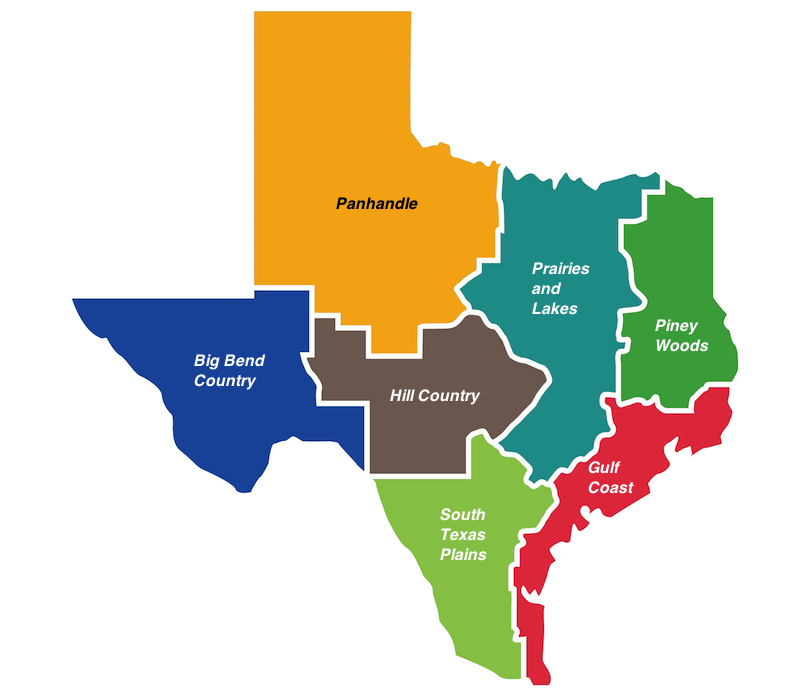
Texas is the second largest state by geographic size, totaling 261,232 sq. miles (to get an idea of how big that really is, click here). One common way to characterize Texas’s geography is by falling into one of six distinct regions:
Big Bend Country
Panhandle
Hill Country
Prairies and Lakes
Piney Woods
South Texas Plains
Gulf Coast
Texas’s large geographic size has shaped state politics and government. Vast distances have historically limited the ability of individuals to engage in the face-to-face interactions necessary to develop close-knit political institutions (which helps to explain, among other phenomenon, why party machines never really took root in Texas). Vast distances also translated into more costly campaigns, as those seeking office try to reach potential voters across larger election districts or, in some cases, across the state at large. This has, in part, deepened politicians’ reliance on connections with deep pockets as a source of campaign financing. Finally, the size of our state, in conjunction with the lack of political organization and frontier-derived elements of our state’s culture and traditions, produced a situation in which candidates were often rewarded for dramatic styles and attention-seeking antics (think W. Lee “Pappy” O’Daniel, former governor of Texas — the governor of Mississippi in the movie “O Brother, Where Art Thou?” is based on him). This type of political environment may make it easier for political outsiders to win political office (i.e., the OUTSIDER PHENOMENON).
Population
Over the past few decades, Texas has experienced rapid and continued population growth (+4.3 million from 2000 to 2010, and +4 million from 2010 to 2020). This rate of population growth outpaces many other states; for that reason, Texas gained four seats in the U.S. House of Representatives following the 2010 Census and an additional two seats following the 2020 Census.
Today, Texas is the second most populated state in the United States, with a population of over 29.1 million people, of which:
6.9% are under 5 years of age, 25.5% are under 18 years of age, and 12.9% are 65 years of age or older
50.3% are female
41.2% are white, 39.7% are Hispanic or Latino, 12.9% are Black or African American, 5.2% are Asian, 1.0% are American Indian or Alaskan Native, 0.1% are Native Hawaiian or Pacific Islander, and 2.1% are two or more races
NOTE: Texas is one of seven states that are considered a MAJORITY-MINORITY STATE, because less than 50% of the population are non-Hispanic white persons
17% were foreign-born persons
The primary sources of Texas’s population growth from 2010-2020 were NATURAL INCREASES (i.e., birthrate) and DOMESTIC MIGRATION (i.e., moving to Texas from another state in the United States). This trend has recently shifted, with domestic migration now accounting for the majority of growth within the state.
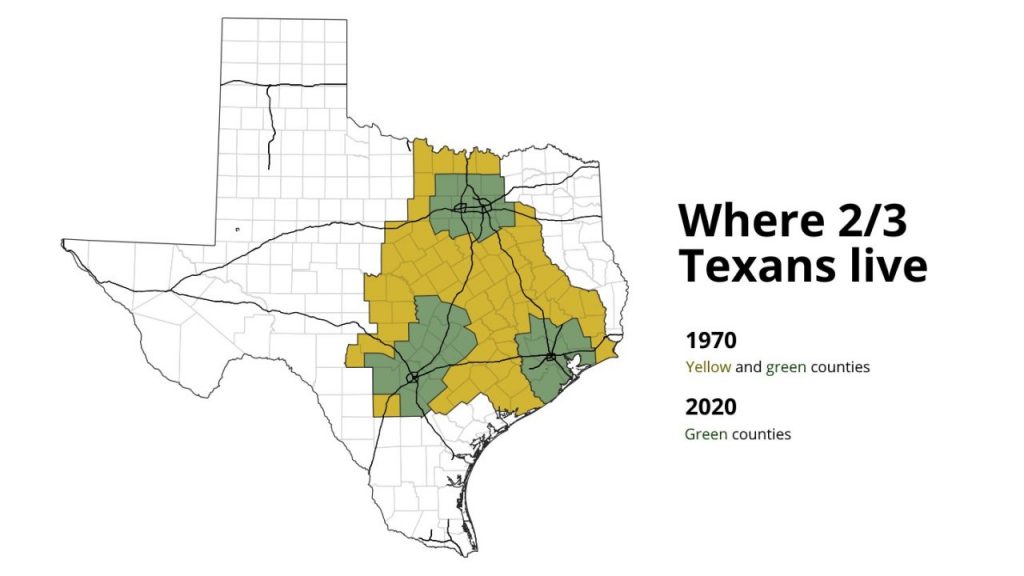
Texas has the largest rural population and the second largest urban population of all the states. While there are still many rural areas in Texas, its population is increasingly residing in urban areas, with 83.7% of Texans living in urban areas in 2020. Three of the largest 10 U.S. cities are in Texas: Houston (#4, with a population of nearly 2.4 million); San Antonio (#7, with a population of nearly 1.6 million); and Dallas (#9, with a population of about 1.4 million). Two-thirds of Texans live in an area that extends between Dallas/Fort Worth, San Antonio, and Houston, known as the TEXAS TRIANGLE.
Texas is sometimes called the “buckle of the Bible Belt”: the majority of Texans are religious, with most religious Texans considering themselves either Catholic, Protestant, or Evangelical Protestant. Texas is among the most religious states (#11 in 2016, according to Pew Research Center).
In several important areas, Texans lag behind other citizens in other states:
Citizen wealth — Texas’s per capita income and household ownership rate fall below the national average; Texas’s poverty rate is higher than the national average
Citizen education — Texas falls in the bottom 1/3 of states when it comes to four-year high school graduation rates and percentage of the population age 25 and older who have a high school diploma and lags behind the national average on percentage of population age 25 and older who have a bachelor’s degree or an advanced degree
For a graphical summary of the 2018 Texas Civic Health Index report, which includes facts regarding where Texas ranks on civic engagement compared to other states, click here.
Economy
Texas has transitioned over time from an economy based largely on agricultural products (cattle, cotton, and lumber), to one dominated by the oil industry, to the highly diversified economy that exists in the state today. Major industries today include energy, agriculture, manufacturing, and information technology.
Today, Texas’s GDP (GROSS DOMESTIC PRODUCT) is the second largest among all states ($2.6 trillion in 2023) and is larger than the GDP of some countries. Texas also comes in second among all states when it comes to the total number of jobs (14.09 million in Nov. 2023). Not only do we have a lot of jobs, but we also have a lot of job creation:
According to the Bureau of Labor and Statistics (BLS), in 2023 Texas ranked #1 in job creation and #3 in over-the-year percent change
According to the Texas Workforce Commission (TWC), December 2023 marked 34 months of uninterrupted job growth and new record highs for the number of jobs in Texas, the number of Texans working, and the size of the Texas labor force
“Texas has always been an export-based economy, with first cotton, then energy and now high-tech linking it to global markets” (The future is – Texas; Texas, 2002). Today, Texas leads in exports, with the highest export rate of all states ($315.9 billion in 2018, which made up 17.3% of the state’s GDP). The largest export product is oil and gas.
During Rick Perry’s time as governor, many businesses, including major automotive manufacturing and information technology companies, opened new locations and/or relocated their corporate headquarters to Texas. This trend has continued during Greg Abbott’s governorship — Tesla’s decision to construct the Gigafactory automotive manufacturing facility in Austin (and their more plans to construct the “Bobcat Project” facility next to the Gigafactory) is one of numerous examples of businesses choosing to expand their operations within our state. In total, over 150 business have moved or have announced they are moving to Texas since 2020; more than half of these businesses are moving from California.
This raises the question: why do businesses like Texas?
favorable tax policies, including low taxes and generous subsidies
business-friendly regulations
low cost of living, corporate rent, and real estate
Texas’s government, politics, and political culture are heavily influenced by our state’s unique history and the legends it inspired; thus, it helps to have a basic understanding of our history.
Six Flags Over Texas
Texas has been part of six different nations:
Spain (1519–1821)
France (1685–1690)
Mexico (1821–1836)
the Republic of Texas (1836–1845)
the Confederate States of America (1861–1865)
the United States of America (1845–1861; 1865–present)
Indigenous Tribes & European Colonization
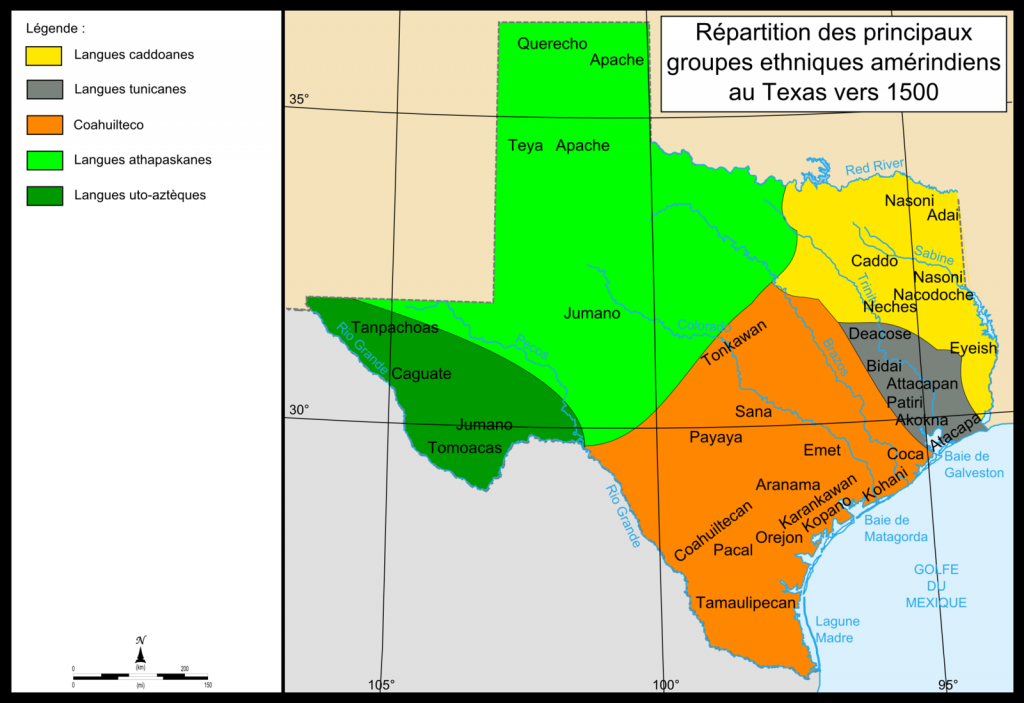
Texas has been characterized by diversity since the beginning: several diverse and well-established indigenous tribes lived in Texas when European and French exploration of the area began.
French exploration and settlement in Texas under La Salle was brief and limited; however, French presence in the area did spur Spain to increase its presence in Texas, establishing a system of MISSIONS and PRESIDIOS.
Initially, Spain was resistant to immigration to Texas from the United States; however, this changed in the early 1800s. Following the negotiation of the ADAMS-ONIS TREATY in 1819, which more clearly defined the boundary between the U.S. and Mexico, Spain sought to develop a stronger presence in Texas and “buffer” against U.S. expansion through the recruitment of Anglo-American immigrants via land grants. This is where EMPRESARIOS come into play. The first of these were Moses Austin and his son, Stephen F. Austin. Moses was awarded a contract (fulfilled by his son following his death) to bring the original Anglo-American settlers to Texas (a total of 300 families).
Mexico
Under Mexican governance, the work of the empresarios continued, and by 1830, Anglo settlers made up a significant portion of the population in Texas. Although Mexico had hoped that the empresarios and new settlers would become loyal to Mexico, tensions rose, fueled by differences in political culture, the Mexican government’s insistence on Spanish as the official language and Catholicism as the official religion, and the issue of slavery. Some empresarios, including Austin, and Anglo settlers were loyal to the Mexican government; others were not. Haden Edwards led a group of Anglo settlers in Texas to secede from Mexico and establish the (short-lived) Republic of Fredonia near Nacogdoches in what is known as the FREDONIAN REBELLION. While this “rebellion” was not successful, it illustrates the rising tensions in Texas during this time period.
The Mexican government eventually modified laws to allow English as an official language, and made some other changes to accommodate the demands of the Anglo-American settlers; however, tensions remained. In 1829, the GUERRERO DECREE formally abolished slavery in all Mexican territories, including Texas. The following year, Mexico banned immigration from the U.S. Then, in 1833, SANTA ANNA, a CENTRALISTA, was elected president of Mexico. Santa Anna repealed the Federal Constitution of the United Mexican States of 1824 in favor of adopting a more unitary system of government in which power would be concentrated in the national government, with less local governing authority, which was not well received by many Tejanos and Texians.
The actions taken by Santa Anna eventually led to the TEXAS REVOLUTION, which began in 1835 at the Battle of Gonzales and lasted through May 14, 1836, when Santa Anna signed the TREATIES OF VELASCO recognizing Texas’s independence in exchange for his freedom.
Republic of Texas & Path to Statehood
The Republic of Texas was short-lived. Attempts at annexation were made immediately following Texas gaining independence from Mexico; however, the annexation of Texas was extremely controversial. In fact, it was one of the major issues at play in the 1844 election.
Prior to the 1844 election, President Tyler proposed the Tyler-Texas Treaty, which would annex Texas; ultimately, this treaty was defeated in the Senate (treaties require a 2/3 vote of approval in the Senate for ratification, which is a difficult threshold to meet). During the 1844 presidential election, one of the candidates, James K. Polk, framed Texas annexation through the lens of MANIFEST DESTINY, or the belief that U.S. expansion throughout the American continents was justified and inevitable. When Polk won the election, Tyler declared Polk’s victory a mandate for Texas annexation and called for the adoption of a joint resolution approved by a majority vote in House of Representatives and Senate (which is an easier threshold to meet than that required of treaties) to officially annex Texas. The annex resolution passed, and the Texas annexation convention passed the Tyler-Polk annexation offer on July 7, 1845.
Secession, Reconstruction, & Redemption
In 1861, Texans voted overwhelmingly in favor of secession, and Texas joined the Confederate States of America. Following the Civil War, Texas, like many other states, experienced PRESIDENTIAL RECONSTRUCTION and, later, RADICAL (or CONGRESSIONAL) RECONSTRUCTION. Radical reconstruction brought with it Republican dominance at the state level, ushered in partially as a result of newly enfranchised African American males and partially as a result of the DISQUALIFICATION CLAUSE of the 14th Amendment, which stripped voting rights from supporters of the Confederacy. After Reconstruction ended, confederate sympathizers began to regain the right to vote, black codes were enacted to make it more difficult for African American males to vote, and the state transitioned to one of Democratic dominance. These Democratic “Redeemers” set out to remove Republican influence from Texas government. “The rise of the Redeemers and the impact of THE GRANGE are especially important transitions in Texas politics because the constitution of this era remained in force long after the politics and politicians responsible for it had vanished” (Collier, Galatas, and Harrelson-Stephens, 2023, p. 15).
Twentieth-Century Transitions
The 20th century marked a time of change for Texas. One such change ushered in the new century: striking oil at SPINDLETOP in 1901. This not only transitioned Texas’s economy from one dominated by “King Cotton” to one dominated by oil (a change which ended up shaping state government and politics) but also marked the beginning of the oil age in the U.S.
In 1928, Texas voted for a Republican presidential candidate for the first time (Herbert Hoover). In 1961, Texas elected a Republican to serve in the U.S. Senate — the first Republican serving in a statewide office since Reconstruction. This marked the beginning of an era of PRESIDENTIAL REPUBLICANISM, with Texans voting for Republicans in national elections and Democrats in state and local elections. During the last two decades of the twentieth century, Republicans began to win local and state elections, and, by the late 1990s, the Republican party had come to dominate state politics in Texas.
Texas is known for a lot of things — political participation is not one of them.
“Due in part to our size and in part to our growth, Texas continues to fall behind the bulk of the nation when it comes to measures such as voting and civic involvement.”- Susan Nold, as quoted by UT News (2018)
Texas ranks near the bottom of the list when it comes to various pathways of civic engagement, including voter registration, voting, donating, volunteering, contacting elected officials, and discussing government and politics. For a graphical summary of the 2018 Texas Civic Health Index report, which includes facts regarding where Texas ranks on civic engagement compared to other states, click here.
Civic engagement is impacted by many factors, including age, wealth, education, and how strongly a person feels about an issue. Generally speaking, older, more educated citizens are those most likely to engage with the government. We see this in Texas: older individuals are those most likely to vote, and college graduates are far more likely to participate in group activities, like volunteering for nonprofit organizations such as Habitat for Humanity. This has serious implications; after all, the government is most responsive to the needs and desires of those who engage.
Increasing Civic Engagement in the Lone Star State
Several recommendations to improve civic engagement in Texas were discussed within the 2018 Texas Civic Health Index report. These recommendations include:
Reimagining civics education to better prepare the next generation for the responsibility of self-governance
Explore opportunities for institutional, systems-level changes by tapping into one of the advantages of federalism and examining what laws other states have regulating political participation to see if we can identify “best practices”
Developing civic leaders by creating educational opportunities that help develop skills associated with civic leadership, service, and running for elected office
Encouraging innovation to reduce obstacles and create new opportunities for civic engagement
Supporting organizations that invest in Texas, such as neighborhood associations and nonprofits
CIVIC ENGAGEMENT refers to participation that connects citizens to government. Civic engagement plays a vital role in politics, particularly in the context of governments that fall into the nonauthoritarian political system, such as the U.S. (recall that the U.S. has an indirect democracy – more specifically, a constitutional federal republic). “In the United States, citizens play an important role in influencing what policies are pursued, what values the government chooses to support, what initiatives are granted funding, and who gets to make the final decisions” (American Government, Ch. 1).
Perhaps the most obvious example of a pathway to civic engagement is voting; however, there are several other ways in which citizens can engage in politics and government.
Civic engagement is impacted by many factors, including age, wealth, education, and how strongly a person feels about an issue. Generally speaking, wealthier, older, and more educated citizens are those most likely to engage with government. This has implications; after all, government is most responsive to the needs and desires of those who engage.
Democracy is a form of government in which power is vested in the people. In a DIRECT DEMOCRACY, political decisions are made directly by the people. In an INDIRECT DEMOCRACY, the people select officials to represent them in the decision-making process.
Fundamental Principles of Democracy
All democratic governments, whether direct or indirect, are based on three fundamental principles:
POPULAR SOVEREIGNTY, or the idea that citizens are the ultimate source of power;
POLITICAL LIBERTY, or the idea that citizens are protected from government interference in the exercise of basic freedoms; and
POLITICAL EQUALITY, or the idea that every person carries equal weight in the conduct of public businesses
While all democracies incorporate these principles into their structure and functions, not all democracies are structured and function the same way. For instance, two countries may have indirect democracies, but the specific institutions that are established within those indirect democracies may differ in terms of their structure, functions, and formal or informal rules concerning who may exercise power. They may also differ in terms of the economic system that they have (i.e., capitalism, regulated capitalism, socialism, or social democracy), which has implications concerning how much control the government has in terms of the economy and when the government feels it is appropriate to intervene in economic matters.
Theories of Democracy
Three theories that seek to explain how power is (or should be) exercised within a democratic government include:
ELITE DEMOCRACY, which claims political power rests in the hands of a small, elite group of people
PLURALIST DEMOCRACY, which claims political power rests in the hands of groups of people
PARTICIPATORY DEMOCRACY, which claims power rests in the hands of people who engage in broad, active, and direct democratic participation in government, industry, education, and community affairs
These theories are not mutually exclusive; in most democratic governments, you will find elements that reflect two or more of these theories. Oftentimes, the way power is exercised within a democratic government can be explained by the TRADEOFFS PERSPECTIVE, which holds that government action and public policy is not controlled solely by the elite, or by groups of people, or by direct and broad participation of individual people but instead is influenced by an ongoing series of compromises between these actors.
Which theories are most prevalent in a government has implications concerning the rights, responsibilities, and obligations of citizens and the way in which these citizens can participate in civic life, gain and exercise power, and effectuate change.